
The AI revolution is pushing models to unprecedented scales, demanding real-time insights from complex data. In addition, agentic AI flows and new human sensory experiences drive new techniques to improve performance and reduce latency. However, traditional CPUs and legacy Network Interface Cards (NIC) in today’s data center servers are fundamentally ill-equipped for AI's unique demands.
Modern data centers are rapidly segmenting to address this:
- Cloud Infrastructure: Leveraging traditional NICs for generalized workloads like virtualization and storage.
- AI-centric Application Deployment: This burgeoning segment demands purpose-built AI-NICs to accelerate demanding AI workloads and enable efficient scale-out.
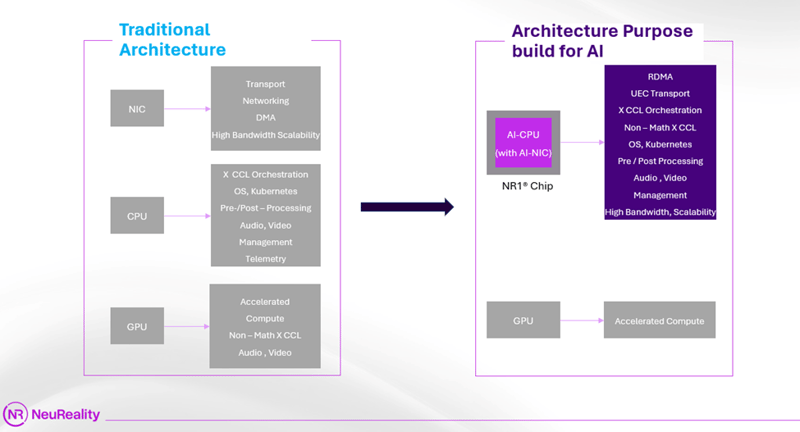
Today’s AI data flows are bottlenecked by head nodes currently using inefficient general-purpose CPUs and congested legacy networks handled by traditional general-purpose NICs and software stacks. For AI to truly scale, both must be optimized. This is precisely where NeuReality’s disruptive technology shines. The NR1® Chip, the first true AI-CPU purpose-built for AI head nodes, replaces general-purpose CPUs and NICs to drive higher efficiency and lower latency required for inference at scale. It integrates a novel networking approach named AI-NIC with advanced techniques to reduce data movement overheads.
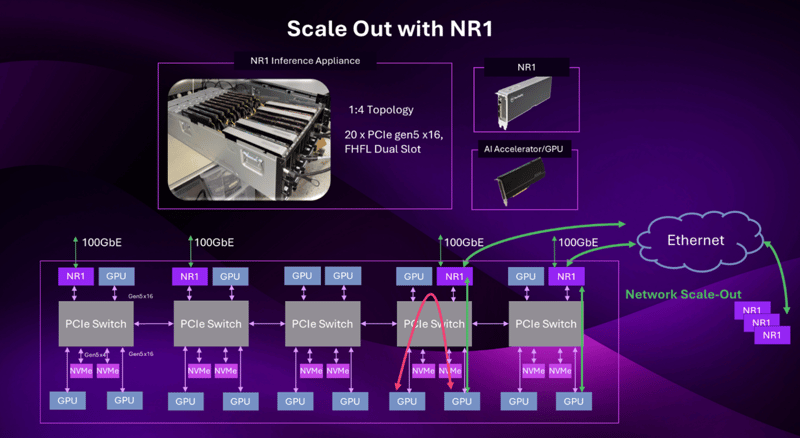
Seamless Scale-Out - Facilitating low latency and communication across nodes within a server, as well as across servers
Dual Bottleneck & The Imperative for AI-NICs
The mismatch between traditional data center computing/networking and AI's modern demands creates critical pain points:
- High Volume AI Traffic: AI training and inference demand constant, intense communication (east-west traffic), overwhelming traditional fabrics. The network engine is at the heart of robust data center scale-out, yet traditional NICs and network software stacks falter under this load.
- Latency Sensitivity: Model synchronization delays severely impact efficiency. Traditional CPUs cannot keep pace, and legacy NICs become a choke point. GPU innovation demands high-performance, scale-out NICs at the core of AI compute – a challenge traditional NICs cannot meet.
- Unpredictable Network Behavior: Congestion and jitter common in general-purpose networks prolong time-to-insight and hinder consistent AI performance.
The data center NIC market is expected to surge past $16 billion by 2028, underscoring the urgency for purpose-built AI networking categories like the AI-NIC.
Today’s general-purpose CPUs and NICs need to be replaced by dedicated AI head-nodes – specialized front end servers that manage incoming AI data and orchestrate the workloads. By 2030, AI head nodes are projected to dominate a reorientation that, paired with Gartner's forecasted AI server market surge, unequivocally demands AI-optimized infrastructure.
This is precisely why NeuReality designed AI-NIC capabilities directly into its NR1 Chip, specifically targeting the acceleration via optimized AI head nodes.
The NR1 Chip: Smashing Scale Barriers with Integrated AI-NIC
Our revolutionary NR1 Chip fundamentally redefines AI infrastructure. By integrating advanced AI-NIC architectural capabilities and compute, it works in harmony with any GPU or AI Accelerator, directly eliminating the dual bottleneck that cripples AI performance today. Unlike other solutions that offer specialized network acceleration, the NR1 Chip provides a more complete, integrated, and efficient approach by consolidating and optimizing key elements of the AI pipeline within a single, powerful chip.
Here’s how the NR1 Chip, with its integrated AI-NIC architecture, stands out:
-
Flexible & Extensible Networking: Features an AI-Aware “4.5” AI-over-Fabric® network engine for low-latency, inference-optimized fabric. It includes Host Bypass for direct data-path and job management (reducing CPU overhead), and boasts Multi-Tiered Processing combining custom hardware, RISC cores, and Arm cores for balanced flexibility and performance.
-
Innovative AI Acceleration Engine: Integrates the NR1® AI-Hypervisor® for hardware-based control, orchestrating multiple AI jobs with direct connection to the networking stack. This enables pre & post processing offload, freeing host resources and speeding up the AI pipeline via Built-in Data Path Acceleration optimized for inference.
-
AI-Aware Network Function Offload: Offers programmable hardware acceleration for workload-specific network behavior. It manages advanced packet processing (parsing, classification, modification) and provides comprehensive network stack offloads (TCP LRO/TSO, protocol validation). Direct data placement ensures zero-copy efficiency to AI app memory.
Our built-in networking transforms your data center, delivering AI scale-out with no excess or compromise. This makes your network not just a utility, but a strategic advantage for AI at scale.
Don't let legacy infrastructure hold you back; embrace purpose-built AI solutions to secure your competitive edge.
Let's talk.
Contact Us today to learn more.
Or email to set up a discussion with Guarav Shah, VP Business Development, NeuReality at: gauravs@neurealiy.ai


